
Voici la suite des tests de cache...
Dans l’épisode précédent de nos benchs, nous avions des requêtes en erreur, ce qui n’est pas satisfaisant.
Après analyse, il y avait plusieurs effets qui perturbaient les tests :
- L’effet Réseau : les tests étaient lancés depuis une machine distante, derrière une connexion ADSL, et certaines des erreurs pouvaient en découler. En particulier, il semble que certains boitiers bloquent des requêtes trop nombreuses vers une même URL. Nous avons donc changé de support de test, en utilisant un serveur (dédibox), mais situé sur un réseau différent du serveur cible (gandi).
- Le nombre de maxClient pour Apache, s’il est trop élevé, peut entrainer un écroulement du serveur par excès de processus lancés, de consommation mémoire, et swap trop intensif. Nous avons donc optimisé cette configuration d’Apache afin que le serveur reste stable dans tous les cas.
Enfin, pour assurer une reproductibilité des résultats, nous avons pris le parti de rebooter la machine avant chaque test pour être sûr que le serveur soit tout propre et dans les mêmes conditions. Nous faisons aussi toujours un hit manuel sur la page testée pour assurer la mise en cache préalable.
On retrouve cette fois des résultats constants quelle que soit la concurrence des requêtes arrivant sur le serveur :
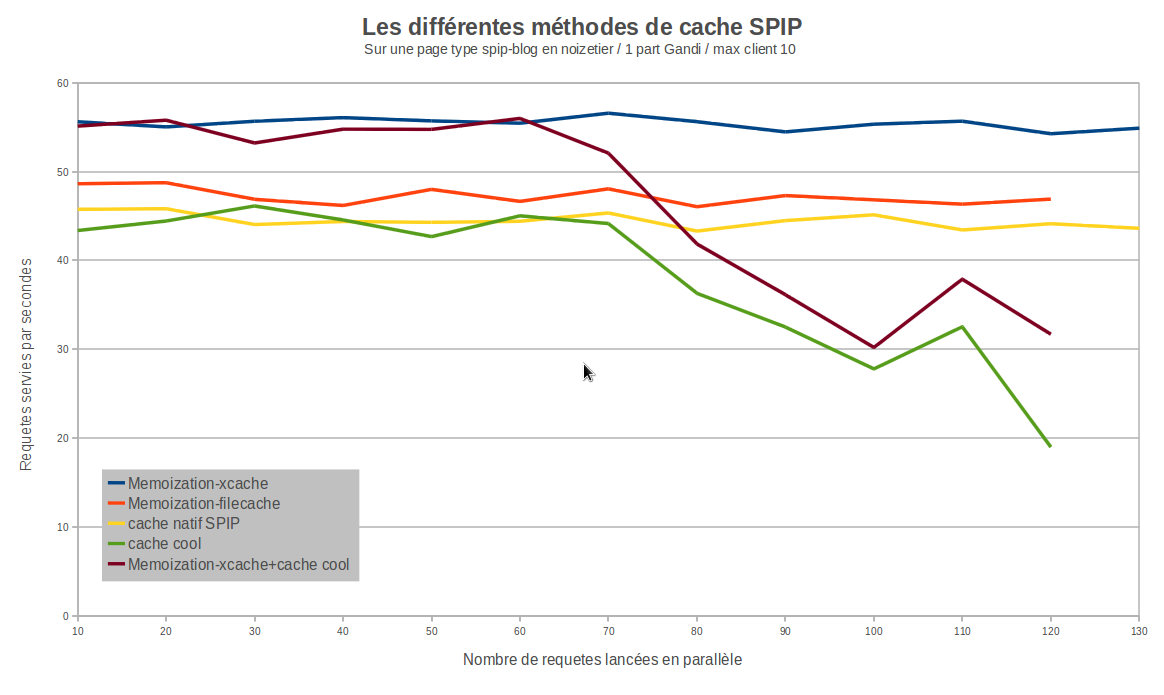
Seule la configuration avec Cache-Cool reste problématique, comme précédemment expliquée. C’est le seul cas où l’on constate des requêtes en erreur.

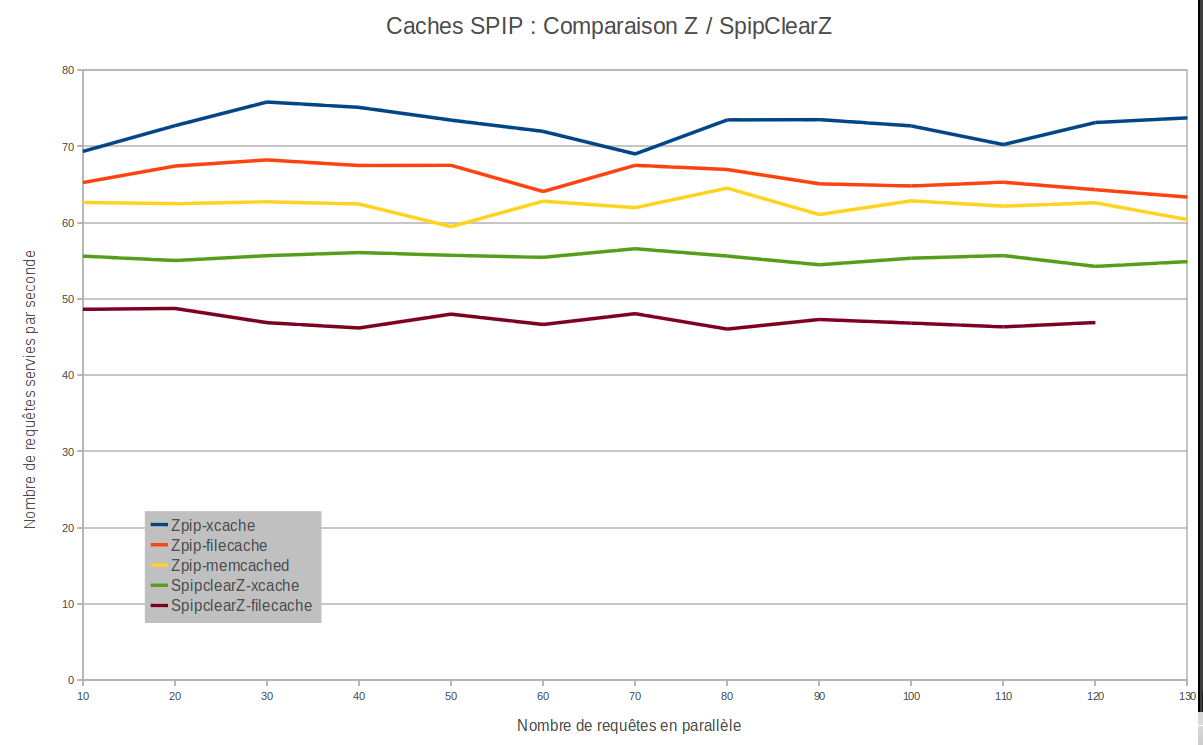
A noter que la nature du squelette peut également avoir un impact sur les résultats. Pour mémoire et futur benchs, voici le graphe correspondant à une page du style ZPIP contre une page concernant SPIP-ClearZ.
Pour finir, je me permet de vous faire partager ce petit plaisir. Quand on lance le script, on voit
** SIEGE 2.66
** Preparing 110 concurrent users for battle.
The server is now under siege...Je trouve cela amusant !
clipart par Elliott Edwards
Vos commentaires
# Le 14 février 2011 à 18:06, par Fil En réponse à : Les différentes méthodes de Cache pour SPIP - Episode II
En réponse à : Les différentes méthodes de Cache pour SPIP - Episode II
Bien voilà qui me rassure, tout correspond à ce qu’on pouvait attendre ; seule petite surprise, memcache qui se trouve être plus lent que filecache. Mais peut-être que vos tests ont été faits sur une machine pas trop chargée par ailleurs, avec des I/O libres de répondre vite.
# Le 24 mai 2011 à 10:14, par Loiseau2nuit En réponse à : Les différentes méthodes de Cache pour SPIP - Episode II
En réponse à : Les différentes méthodes de Cache pour SPIP - Episode II
Même surprise que Fil sur ce coup là ... oO
Selon vous, d’un squelettes à l’autre, c’est quoi qui change la donne, les requêtes faites au titre de la surcharge ?
# Le 12 mars 2015 à 14:20, par Valery En réponse à : Les différentes méthodes de Cache pour SPIP - Episode II
En réponse à : Les différentes méthodes de Cache pour SPIP - Episode II
Même question que Loiseau : qu’est-ce qui dans les squelettes a le plus d’impact ? Existe-t-il svp de bonnes pratiques documentées pour les optimiser ?
# Le 23 octobre 2020 à 21:58, par Major En réponse à : Les différentes méthodes de Cache pour SPIP - Episode II
En réponse à : Les différentes méthodes de Cache pour SPIP - Episode II
Manyy thanks ! I ebjoy it ! Best Essay writing the book hiroshima
# Le 18 novembre 2020 à 21:06, par Lyndon En réponse à : Les différentes méthodes de Cache pour SPIP - Episode II
En réponse à : Les différentes méthodes de Cache pour SPIP - Episode II
Wonderful material, Withh thanks ! Best Esssay writing economics essay
Répondre à cet article
Suivre les commentaires : |
|
